Summary
Platform
Prompt CRUD APIs Prompt CRUD APIs give you the control to scale by enabling you to:- Programmatically create, update, and delete prompts
- Manage prompts in bulk or version-control them
- Integrate prompt updates into your own tools and workflows
- Automate updates for A/B testing and rapid experimentation
- Allocate specific budgets to different departments, teams, or projects
- Prevent individual workspaces from consuming disproportionate resources
- Ensure equitable API access and complete visibility
- Unified AI Gateway: Connect to 1600+ models with full API key management—not just OpenAI or Anthropic.
- Centralized observability: Track 40+ metrics and request logs in real time.
- Governance: Monitor spend, set budgets, and apply RBAC across workflows.
- Security guardrails: Enable PII detection, content filtering, and compliance controls.
- Access to 250+ additional models beyond OpenAI Codex CLI’s standard offerings
- Content filtering and PII detection with guardrails
- Real-time analytics and logging
- Cost attribution, budget controls, RBAC, and more!
- Introduced a new retry setting
use_retry_after_header. When set to true, if the provider returns theretry-afterorretry-after-ms headers, the Gateway will use these headers to determine retry wait times, rather than applying the default exponential backoff for 429 responses. - You can now store and retrieve vector embeddings for semantic cache using Milvus in Portkey. Read more in Cache (Simple & Semantic).
- Plugins have now been moved under Settings (org-level) in the Portkey app.
- Virtual Key exhaustion alert emails now include which workspace the exhausted key belonged to.
- Set up your workspace with Workspace control on the Portkey app.
Gateway & Providers
OpenAI embeddings response We’ve optimized the Gateway’s handling of OpenAI embeddings requests, leading to around 200ms improvement in response latency. Responses API You can now use the Responses API to access OpenAI and Azure OpenAI models on Portkey, enabling a flexible and easier way to create agentic experiences.- Complete observability and usage tracking
- Caching support for streaming requests
- Access to advanced tools — web search, file search, and code execution, with per-tool cost tracking
- Cache specific portions of your requests for repeated use
- Reduce inference response latency and input token costs
- No extra setup required
- Stay in control with logs, traces, and key metrics
- Manage all your LLM interactions through one interface
- Openrouter: Added mapping for new parameters - modalities, reasoning, transforms, provider, models, response_format.
- Vertex AI: Added support for explicitly mentioning mime_type for urls sent in the request. Gemini 2.5 thinking parameters are now available.
- Perplexity: Added support for response_format and search_recency_filter request parameters.
- Bedrock: You can now pass the
anthropic_betaparameter in Bedrock’s Anthropic API via Portkey to enable Claude’s Computer use beta feature.
Dashscope
Integrate with Dashscope
Recraft AI
Generate production-ready visuals with Recraft
Replicate
Run open-source models via simple APIs with Replicate
Azure AI Foundry
Access over 1,800 models with Azure AI Foundry
- Caching and Logging Unified Thinking Responses: Unified thinking response (content_blocks) now logged and cached for stream responses.
- Strict Metadata Enforcement: The metalogging preference order now is
Workspace Default > API Key Default > Incoming Request. This is provide better control to org admins and ensure values set by them are not overridden. - Prompt render endpoint: Previously only available via the control plane, the prompt render endpoint is now supported directly on the Gateway URL.
- Default config in an API key can no longer be overridden.
New Models & Integrations
GPT-4.1
OpenAI’s new model for faster and improved responses
Gemini 2.5 Pro
Google’s most advanced model
Gemini 2.5 Flash
Google’s fast, coest-efficient thinking model
Llama 4
Meta’s latest model via Fireworks, Together, and Groq
o1-pro
OpenAI’s model for better reasoning and consistent answers
gpt-image-1
OpenAI’s latest image generation capabilities
Qwen 3
Alibaba’s latest model with hybrid reasoning
Audio models
Access audio models via Groq
Guardrails
- Azure AI content safety: Use Microsoft’s content filtering solution to moderate inputs and outputs across supported models.
- Exa Online Search: You can now configure Exa Online Search as a Guardrail in Portkey to enable real-time, grounded search across the web before answering. This makes any LLM capable of handling current events or live queries without needing model retraining.
Documentation
Administration Docs
- Provider access permissions: Defining who can view and manage providers within workspaces. Learn more
- API keys access: Control how workspace managers and members interact with API keys within their workspaces. Learn more
Community
Here’s a tutorial on how to build a customer supporr agent using Langraph and Portkey. Shoutout to Nerding I/O!!
Customer love!
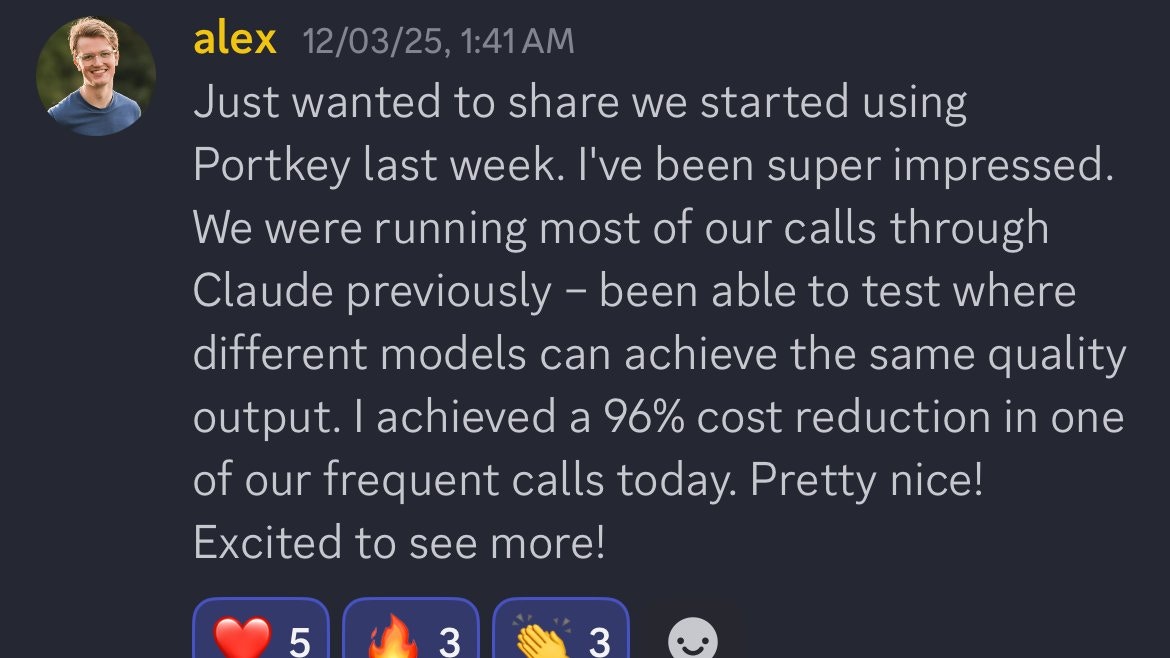 | 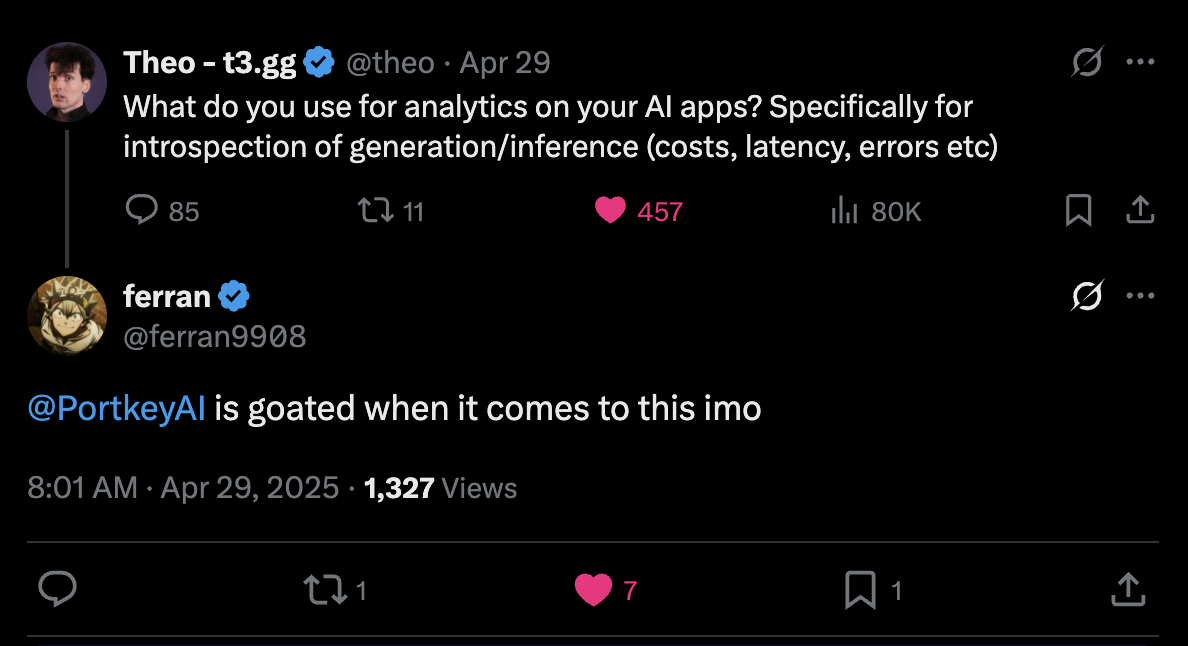 |
|---|
Community Contributors
A special thanks to our community contributors this month:Coming this month!
We’re changing how agents go to production, from first principles. Watch out for this 👀Support
Need Help?
Open an issue on GitHub
Join Us
Get support in our Discord